Har du kollat våra simuleringar och animeringar? Vi, SFK-StaM, lägger då och då ut en…
Mått, KPI och andra kladdiga giftigheter
Vi stöter ofta på numeriska uppgifter både i nyhetsmedia och i arbetslivet, alltifrån matsvinn till utsläpp från bilar. Avsikten är att vi på ett eller annat sätt skall förhålla oss till dessa värden. Vissa av dem är, åtminstone till synes, lätta att förstå medan andra har fysikaliska enheter vars innebörd man kanske glömt.
Det är dock nödvändigt att fråga sig hur t.ex. måttet definieras, hur det mäts, osv. Sifferuppgiften för t.ex. matsvinn i kg per person är mycket varierande och man kan fundera på om det verkligen är mätningar som ligger till grund. (Jag bär ofta ut en påse med komposterbart avfall men det är mest kaffesump, apelsinskal eller skalade grönsaker: är detta matsvinn?)
Utsläpp per bil är en annan knepighet: när nu Volvo satsar på några hundra tusen elbilar blir ju nämnaren mycket större och – vips – sjunker utsläppet per bil eftersom dessa elbilar också får räknas in.
Om man tittar på nätet om KPI (Key Performance Indicator eller ’nyckeltal’) får man en mängd olika exempel, kanske med en viss övervikt till ekonomiska tal typ ROI, P/E. Man hittar även en mängd PowerPoint-råd inklusive en massa självklarheter.
Jag vill i stället diskutera i utifrån ett ’kvalitetsarbetesperspektiv’ och fundera lite på det som inte anges i de käcka PP-texterna. En KPI skiljer sig inte i sak från andra typer av mätningar så tankar kring dessa är också applicerbara på en KPI.
En funktion?
’Långsiktighet’ är ju ett honnörsord och då kan man fundera på varför man väljer ett (1) numeriskt värde som nyckeltal. Det vore bättre att ange en matematisk funktion enligt följande resonemang:
”Idag har vi felkvoten X% på våra produkter, men om tre år skall vi vara nere i Y%. Vi skall klara detta genom ett intimt samarbete med våra underleverantörer och vår produktutveckling.”
Att omformulera detta till en matematisk funktion är inte speciellt krångligt. Sedan är det lättare att följa utvecklingen och verifiera att förbättringarna fortskrider enligt plan. I varje läge kan man göra en statistisk utvärdering och till och med en prediktion om sannolikheten att nå målet.
Ett sant exempel är ”…skall öka medlemsantalet med 5%, 12% respektive 20% under 2007-2009 relaterat till medlemsantalet 2006”. Antag att antal medlemmar vid början av 2006 är 600, då är målet 720 medlemmar vid slutet på 2009. Med lite matematik omformas detta till följande:
antal = 600 * exp(0.061*(år – 2006))
Detta uttryck kan lätt ritas som en graf på vilken man kan lägga utfallet kontinuerligt.
Flera mål?
På senaste WQD (World Quality Day) nämndes att ett ekonomiskt mål uppnåtts med råge medan ett annat, typ utsläpp, tyvärr hade överskridits. Det tyder på en alltför lättvindig syn på målen. I ett seriöst ingenjörssammanhang hade man tagit fram stora optimeringshandboken och hittat hur man skall göra vid ’optimering med restriktioner’ för att hålla alla mål och begränsningar.
Anlägga en processyn?
Jag har sett förslag på KPI som ’max 150 personer i kön till…’. Men kölängden är en mätning som utsätts för variation så det är mycket bättre att titta på processens egenskaper dvs ’flöde in’ och ’flöde ut’. Om förhållandet dem emellan är fel kommer kölängden att variera. Man bör alltså formulera mål som synar processen.
Ett annat exempel: Ett företag hade definierat ’max 1 pixelfel per skärm’ som mål vid inköp av en liten standardskärm till sin produkt. Det inses lätt att sortering hos leverantören kunde sortera ut alla skärmar med 1 pixelfel och leverera dem till företaget. Skärmar utan fel kunde sålunda levereras till andra kunder för kanske ett högre pris.
Vi som jobbade på företaget förslog en processyn: om leverantören kunde visa att processen av skärmar hade mindre än 0.008 pixelfel per skärm skulle sannolikheten att få en skärm med 1 pixelfel vara 0.005, något som kunde hanteras inom garantiåtaganden.
(Nu blev det inte denna lösning, i stället förbjöd företaget pixelfel och satte kravet till 0 pixelfel per skärm. Detta är det samma som att förbjuda variation vilket som bekant inte är en framkomlig väg…)
Ytterligare ett exempel: Om du får reda på att tre olika men jämförbara sjukhus har 10% av väntetiderna mer än 100 dagar är det ganska självklart att påstå att de är lika bra (eller lika dåliga).
Men om du också får reda på att sjukhus A har 40 dagar i snitt, sjukhus B har 60 dagar i snitt och sjukhus C 80 dagar i snitt blir bedömningen kanske annorlunda. Denna fördelning är helt möjlig och antagligen skulle sjukhus A få åtminstone ekonomernas gillande.
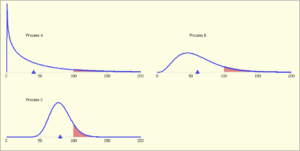
Bilden visar tre tidsfördelningar över 0-200 dagar. Alla tre har, tyvärr, 10 procent mer än 100 dagar (skuggade ytan). Men process A har 40 dagar i snitt, process B 60 dagar i snitt och process C har 80 dagar i snitt. Enligt en ’procentbedömning’ är de tre processerna lika men det är enorma skillnader i medelvärde. Användningen av procent som bedömning är alltså inte speciellt bra.
Variation av KPI?
Eftersom KPI består av ett ändligt antal mätningar från något urval, så innehåller det variation. En uppenbar fråga är ju om denna variation påverkar slutsatserna i någon högre grad. Eller tvärtom: man hittar ingen eller liten variation.
Ett exempel: ett företag sydväst om Stockholm hade hand om datatrafiken för ett antal andra företag. Som KPI hade man medelvärdet ’Antal avbrott per tidsenhet’. Tyvärr visade medelvärdets variation brister i kvalitetsstyrningen, vilket oroade kunderna så man bytte till att ange medianen i stället för medelvärdet. En analys visade att medianen var en mycket mer robust KPI som inte påverkades av den bristfälliga kvalitetsstyrningen så kunderna slapp att oroa sig, vilket ju var bra…
Verifiering av KPI?
Ibland kan du göra en matematisk analys, men jag föreslår ibland en simulering eller annat sätt göra en känslighetsanalys. Ofta är KPIn sammansatt av flera delar och genom att variera och summera dessa får man en uppfattning om den variation som bärs över till KPIn.
Ett exempel: ett företag som tillverkade elektronikdelar skapade en KPI som bestod av en kvalitetsdel, en kvantitetsdel samt ett effektivitetsmått. Sammansättning av dessa förhandlades fram med facket och om resultatet för en tidsperiod överskred ett visst värde, skulle personalen få extra lönepott.
Det visade sig snart att detta gränsvärde överskreds ofta på grund av den slumpmässiga variationen utan någon egentlig höjning av kvalitet, kvantitet eller effektivitet.
Företaget vill ganska snart göra en omförhandling men facket stretade emot (fick dock ge sig när förhandlingarna höjdes till central nivå). Om man hade försökt att simulera utfallet med t.ex. gamla mätvärden hade svagheten kanske uppmärksammats.
Hur syna målsnöret?
När du väl bestämt en KPI bör det finnas ett sätt att avgöra om målet nåtts eller följs. Inom klassisk statistisk analys gör man en hypotesprövning dvs man har en hypotes och mot denna ställer man mätresultatet. Sedan drar man slutsatsen ’Ja’ eller ’Nej’.
En verifiering av en KPI bör ha en liknande neutral procedur speciellt om t.ex. bonusar är baserade på resultatet.
Avslutning
En KPI bör alltså formuleras och konstrueras med största omsorg. Inte sällan är det värt besväret att prata med någon som har kunskap om statistisk teori, analys, variation, modeller, summering av komponenter, etc.
Det är ju trots allt slöseri med tid och pengar om en KPI saknar värde och förlorar sin respekt.
Ingemar Sjöström, SFK-StaM
Relaterade inlägg

